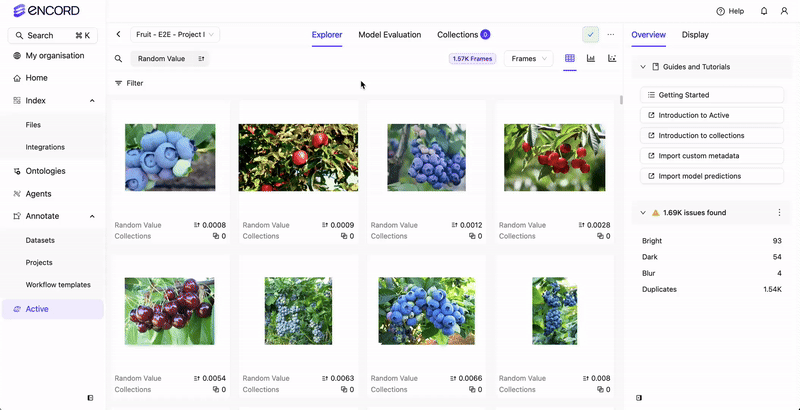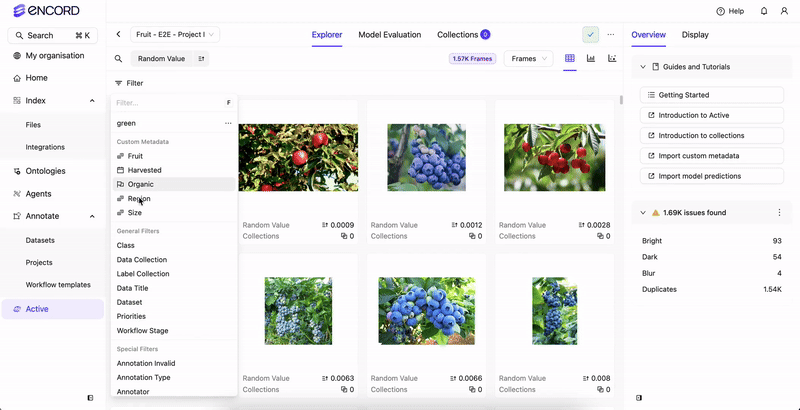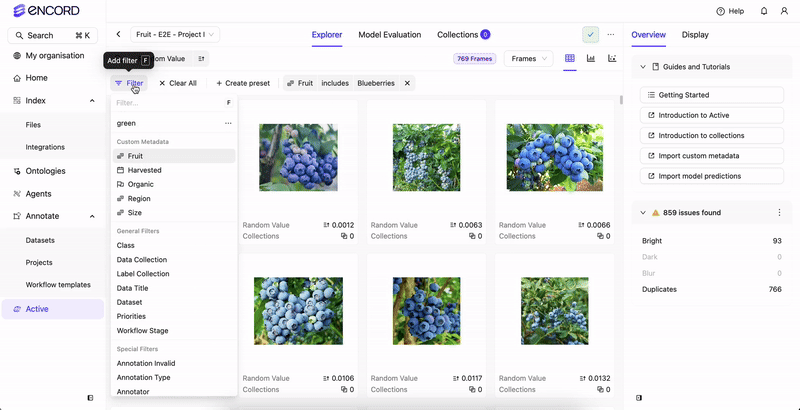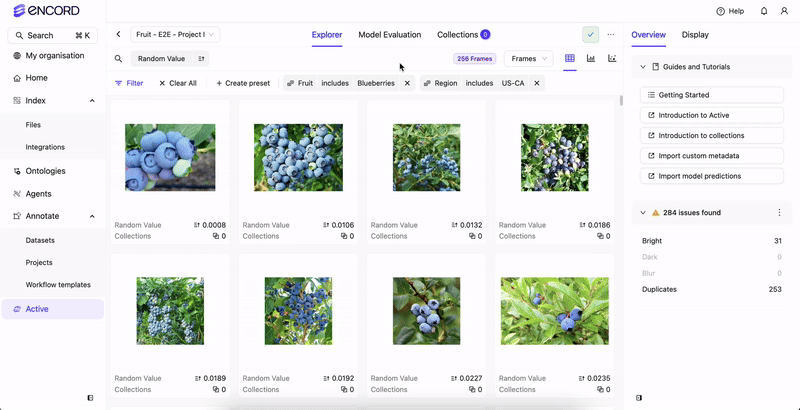
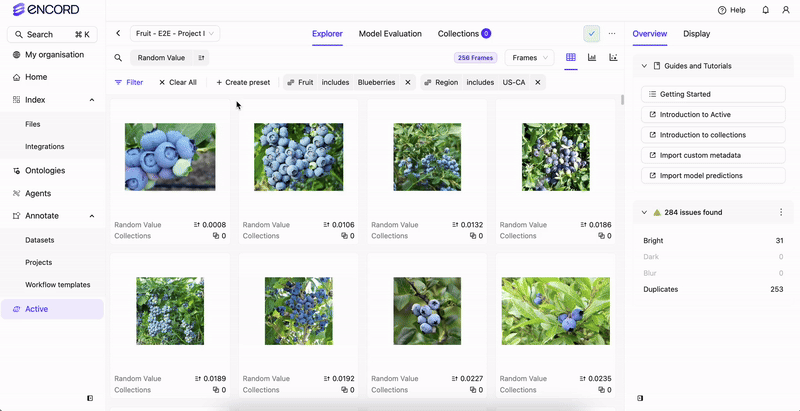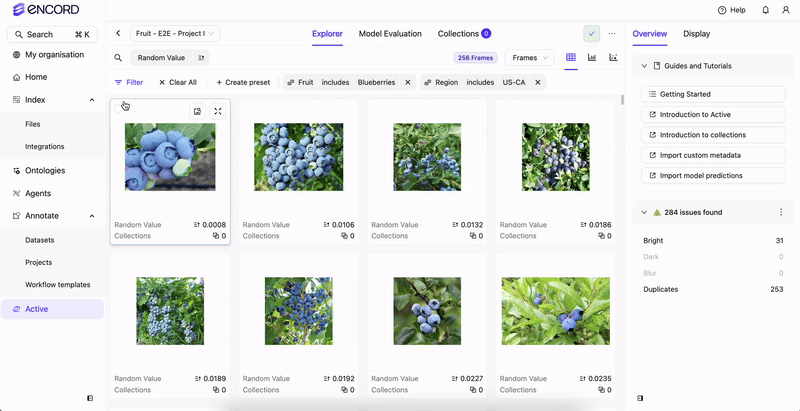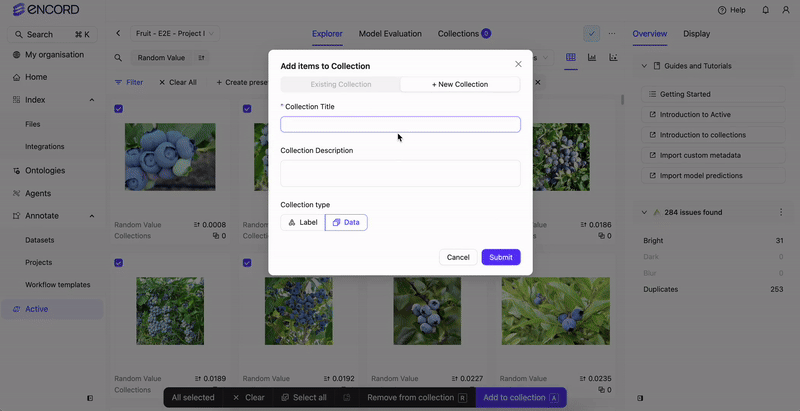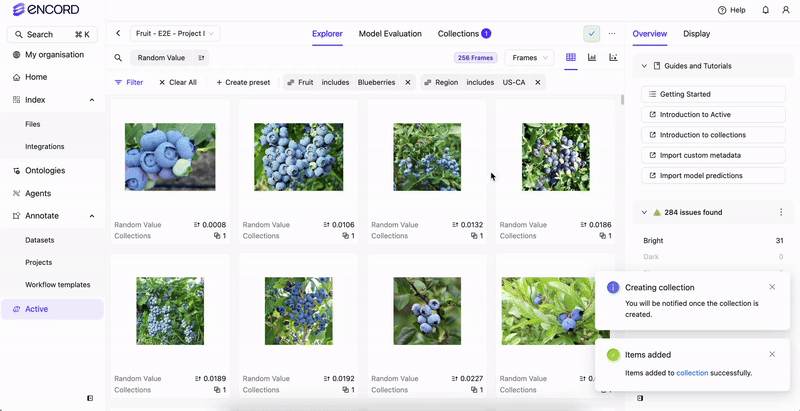
Before you can filter your data or create a Collection based on your data’s custom metadata, the custom metadata must exist in your Annotate Project.
This content applies to custom metadata (clientMetadata), which is the metadata associated with individual data units. This is distinct from videoMetadata that is used to specify video parameters when using Strict client-only access. It is also distinct from patient metadata in DICOM files.
Custom metadata (clientMetadata) is accessed by specifying the dataset using the <dataset_hash>. All Projects that have the specified Dataset attached contain custom metadata.
Performing multiple schema imports overwrites the current schema with the new schema.
Before importing your custom metadata, we recommend importing a metadata schema. Schemas help Encord validate your custom metadata and instruct Index and Active how to display it.
To manage custom metadata across multiple teams, we recommend using namespaced keys in your schema. This helps avoid conflicts—for example, one team might use video.description, while another uses audio.description or TeamName.MetadataKey. It keeps things organized and clear across departments.
Using a metadata schema provides several benefits:
Validation: Ensures that all custom metadata conforms to predefined data types, reducing errors during data registration and processing.
Consistency: Maintains uniformity in data types across different datasets and projects, which simplifies data management and analysis.
Filtering and Sorting: Enhances the ability to filter and sort data efficiently in the Encord platform, enabling more accurate and quick data retrieval.
Metadata Schema keys support letters (a-z, A-Z), numbers (0-9), and blank spaces ( ), hyphens (-), underscores (_), and periods (.). Metadata schema keys are case sensitive.
If you are unsure about the type to assign to a metadata key, we recommend using varchar as a versatile default.
Use .add_scalar() to add a scalar key to your metadata schema.
Scalar Key
Description
Display Benefits
boolean
Binary data type with values “true” or “false”.
Filtering by binary values
datetime
ISO 8601 formatted date and time.
Filtering by time and date
number
Numeric data type supporting float values.
Filtering by numeric values
uuid
UUIDv4 formatted unique identifier for a data unit.
Filtering by customer specified unique identifier
varchar
Textual data type. Formally string. string can be used as an alias for varchar, but we STRONGLY RECOMMEND that you use varchar.
Filtering by string.
text
Text data with unlimited length (example: transcripts for audio). Formally long_string. long_string can be used as an alias for text, but we STRONGLY RECOMMEND that you use text.
Storing and filtering large amounts of text.
Use add_enum and add_enum_options to add an enum and enum options to your metadata schema.
Key
Description
Display Benefits
enum
Enumerated type with predefined set of values.
Facilitates categorical filtering and data validation
Use add_embedding to add an embedding to your metadata schema.
Use add_geospatial to add a new geospatial type to the metadata schema.
Key
Description
Display Benefits
geospatial
Geospatial data that contains latitude and longitude information. Latitude values are between +90 (North) to -90 (South). Longitude values are between +180 (West) to -180 (East).
Filtering data by using a geospatial map.
Geospatial custom metadata is supported only in Index.
Geospatial custom metadata can be applied to all data unit types and on individual frames in videos.
Incorrectly specifying a data type in the schema can cause errors when filtering in Index or Active. To fix this, check your schema, correct any issues, re-import it, and re-sync your Active project.
Deprecated
While still supported, we STRONGLY RECOMMEND that you use the latest metadata schema instructions.
ENUM Name
String Representation
Description
Display Benefits
NUMBER
number
Numeric data type supporting float values
Filtering by numeric values
STRING
string
Textual data type
Filtering by string
BOOLEAN
boolean
Binary data type with values “true” or “false”
Filtering by binary values
DATETIME
datetime
ISO 8601 formatted date and time
Filtering by time and date
ENUM
enum
Enumerated type with predefined set of values
Facilitates categorical filtering and data validation
Text data with unlimited length (example: transcripts for audio)
Storing and filtering large amounts of text
Incorrectly specifying a data type in the schema can cause errors when filtering your data in Index or Active. If you encounter errors while filtering, verify your schema is correct. If your schema has errors, correct the errors, re-import the schema, and then re-sync your Active Project.
After importing your schema to Encord we recommend that you verify that the import is successful. Run the following code to verify your metadata schema imported and that the schema is correct.
# Import dependenciesfrom encord import EncordUserClientfrom encord.metadata_schema import MetadataSchemaSSH_PATH = "<file-path-to-ssh-private-key>"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH)# Create the schemametadata_schema = user_client.metadata_schema()# Print the schema for verificationprint(metadata_schema)
Deprecated
This is supported, as is, we STRONGLY RECOMMEND that you use the most current method of creating your custom metadata schema.
# Import dependenciesfrom encord import EncordUserClientSSH_PATH = "<file-path-to-ssh-private-key>"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH)schema = user_client.get_client_metadata_schema()print(schema)
You can change the data type of schema keys using the .set_scalar() method. The example below shows how to update the data type for multiple metadata fields.
Restore Schema Key
# Import dependenciesfrom encord import EncordUserClientfrom encord.metadata_schema import MetadataSchemaSSH_PATH = "/Users/chris-encord/ssh-private-key.txt"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH)# Get your metadata schemametadata_schema = user_client.metadata_schema()# Edit various metadata fieldsmetadata_schema.set_scalar("metadata_1", data_type="number")metadata_schema.set_scalar("metadata_2", data_type="boolean")metadata_schema.set_scalar("metadata_3", data_type="boolean")# Print the schema for verificationprint(metadata_schema)
Schema key options cannot be deleted. Instead, we recommend creating new schema key options to meet your needs and phasing out any that are no longer required.
You can delete schema keys using the .delete() method.There are two types of deletion: hard delete and soft delete. A hard delete permanently removes the key, making it impossible to restore. A soft delete allows you to restore the key later using the .restore_key() method.The following examples show hard delete and soft deletion of a schema key called Fruit.
# Import dependenciesfrom encord import EncordUserClientfrom encord.metadata_schema import MetadataSchemaSSH_PATH = "/Users/chris-encord/ssh-private-key.txt"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH)# Get your metadata schemametadata_schema = user_client.metadata_schema()metadata_schema.delete_key(k: "Fruit", hard: False)# Print the schema for verificationprint(metadata_schema)
Keys that have been soft deleted can be restored using the .restore_key() method. The following example restores a schema key called Fruit.
Restore Schema Key
# Import dependenciesfrom encord import EncordUserClientfrom encord.metadata_schema import MetadataSchemaSSH_PATH = "/Users/chris-encord/ssh-private-key.txt"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH)# Get your metadata schemametadata_schema = user_client.metadata_schema()metadata_schema.restore_key(k: "Fruit")# Print the schema for verificationprint(metadata_schema)
After importing your schema to Encord we recommend that you verify that the import is successful. Run the following code to verify your metadata schema imported and that the schema is correct.
# Import dependenciesfrom encord import EncordUserClientSSH_PATH = "<file-path-to-ssh-private-key>"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH)schema = user_client.get_client_metadata_schema()print(schema)
keyframes is reserved for use with frames of interest in videos. Specifying keyframes on specific frames ensures that those frames are imported into Index and Active. That means frames specified using keyframes are available to filter your frames and for calculating embeddings on your data.
Import keyframes to specific data units in a folder
This code allows you to import keyframes on specific videos in Index. This code DOES NOT OVERWRITE all existing custom metadata on a data unit. It does overwrite custom metadata with existing values and adds new custom metadata to the data unit.
# Import dependenciesfrom encord import EncordUserClient# AuthenticationSSH_PATH = "<private_key_path>"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH,)# Define a dictionary with item UUIDs and their keyframes updatesupdates = { "<data-unit-id>": {"keyframes": [<frame_number>, <frame_number>, <frame_number>, <frame_number>, <frame_number>]}, "<data-unit-id>": {"keyframes": [<frame_number>, <frame_number>, <frame_number>, <frame_number>, <frame_number>]}, "<data-unit-id>": {"keyframes": [<frame_number>, <frame_number>, <frame_number>, <frame_number>, <frame_number>]}, "<data-unit-id>": {"keyframes": [<frame_number>, <frame_number>, <frame_number>, <frame_number>, <frame_number>]}}# Update the storage items based on the dictionaryfor item_uuid, metadata_update in updates.items(): item = user_client.get_storage_item(item_uuid=item_uuid) # make a copy of the current metadata and update it with the new metadata curr_metadata = item.client_metadata.copy() curr_metadata.update(metadata_update) # update the item with the new metadata item.update(client_metadata=curr_metadata)
We strongly recommend that you upload your custom metadata to Folders, instead of importing using Datasets. Importing custom metadata to data in folders allows you to filter your data in Index by custom metadata.
After importing or updating custom metadata, verify that your custom metadata (list the data units with custom metadata) applied correctly. Do not simply add a print command after importing or updating your custom metadata.
Import custom metadata to all data units in a Folder
This code allows you to update ALL custom metadata on ALL data units in a Folder in Index. This code OVERWRITES all existing custom metadata on a data unit.
# Import dependenciesfrom encord import EncordUserClientfrom encord.orm.storage import StorageFolder, StorageItem, StorageItemType, FoldersSortBy# AuthenticationSSH_PATH = "<file-path-to-ssh-private-key-file>"FOLDER_HASH = "<unique-folder-id>"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH,)folder = user_client.get_storage_folder(FOLDER_HASH)items = folder.list_items()for item in items: item.update(client_metadata={"metadata": "value", "metadata": "value"})
Update custom metadata to specific data units in a folder
This code allows you to update custom metadata on specific data units in Index. This code DOES NOT OVERWRITE all existing custom metadata on a data unit. It does overwrite custom metadata with existing values and adds new custom metadata to the data unit.
# Import dependenciesfrom encord import EncordUserClient# AuthenticationSSH_PATH = "<private_key_path>"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH,)# Define a dictionary with item UUIDs and their respective metadata updatesupdates = { # "<data-unit-id>": {"metadata": "metadata-value"}, # "<data-unit-id>": {"metadata": False}, # "<data-unit-id>": {"metadata": "metadata-value"}, # "<data-unit-id>": {"metadata": True}}# Update the storage items based on the dictionaryfor item_uuid, metadata_update in updates.items(): item = user_client.get_storage_item(item_uuid=item_uuid) # make a copy of the current metadata and update it with the new metadata curr_metadata = item.client_metadata.copy() curr_metadata.update(metadata_update) # update the item with the new metadata item.update(client_metadata=curr_metadata)
Bulk custom metadata import to all data units in a Folder
This code allows you to update custom metadata on all data units in a Folder in Index. This code OVERWRITES all existing custom metadata on a data unit.Using bundle allows you to update up to 1000 label rows at a time.
# Import dependenciesfrom encord import EncordUserClientfrom encord.http.bundle import Bundlefrom encord.orm.storage import StorageFolder, StorageItem, StorageItemType, FoldersSortBy# AuthenticationSSH_PATH = "<ssh-private-key>"FOLDER_HASH = "<unique-folder-id>"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH,)folder = user_client.get_storage_folder(FOLDER_HASH)items = folder.list_items()# Use the Bundle context managerwith Bundle() as bundle: for item in items: # Update each item with client metadata item.update(client_metadata={"metadata-1": "value", "metadata-2": False}, bundle=bundle)
Bulk custom metadata import on specific data units
This code allows you to update custom metadata on specific data units in a Folder in Index. This code DOES NOT OVERWRITE existing custom metadata on a data unit. It does overwrite custom metadata with existing values and adds new custom metadata to the data unit.Using bundle allows you to update up to 1000 label rows at a time.
# Import dependenciesfrom encord import EncordUserClientfrom encord.http.bundle import Bundlefrom encord.orm.storage import StorageFolder, StorageItem, StorageItemType, FoldersSortBy# AuthenticationSSH_PATH = "<ssh-private-key>"FOLDER_HASH = "<unique-folder-id>"# Authenticate with Encord using the path to your private keyuser_client: EncordUserClient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path=SSH_PATH,)folder = user_client.get_storage_folder(FOLDER_HASH)updates = { # "<data-unit-id>": {"metadata-1": "metadata-value"}, # "<data-unit-id>": {"metadata-2": False}, # "<data-unit-id>": {"metadata-1": "metadata-value"}, # "<data-unit-id>": {"metadata-2": True}}# Use the Bundle context managerwith Bundle() as bundle: for storage_item in folder.list_items(): # Update each item with client metadata update = updates[storage_item.uuid] storage_item.update(client_metadata=update, bundle=bundle)
We strongly recommend that you upload your custom metadata to Folders, instead of importing using Datasets. Importing custom metadata to data in Folders allows you to filter your data in Index by custom metadata.
The following code lists the custom metadata of all data units in the specified Dataset. The code prints the custom metadata along with the data unit’s index within the dataset.
# Import dependenciesfrom encord import EncordUserClientfrom encord.client import DatasetAccessSettings# Authenticate with Encord using the path to your private keyclient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path="<private_key_path>")# Specify a dataset to read or write metadata todataset = client.get_dataset("<dataset_hash>")# Fetch the dataset's metadatadataset.set_access_settings(DatasetAccessSettings(fetch_client_metadata=True))# Read the metadata of all data units in the dataset.for data_unit, data_row in enumerate(dataset.data_rows): print(f"{data_row.client_metadata} - Data Unit: {data_unit}")
Before importing custom metadata to Encord, first import a metadata schema.
We strongly recommend that you import your custom metadata to Folders, instead of importing to Datasets. Importing custom metadata to data in folders allows you to filter your data in Index by custom metadata.
# Import dependenciesfrom encord import EncordUserClientfrom encord.client import DatasetAccessSettings# Authenticate with Encord using the path to your private keyclient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path="<private_key_path>")# Specify a dataset to read or write metadata todataset = client.get_dataset("<dataset_hash>")# Fetch the dataset's metadatadataset.set_access_settings(DatasetAccessSettings(fetch_client_metadata=True))# Add metadata to a specific data unit by replacing <data unit number> with the number of the data unitdata_row = dataset.data_rows[<data unit number>]# Replace {"my": "metadata"} with the metadata you want to adddata_row.client_metadata= {"my": "metadata"}data_row.save()print(data_row.client_metadata)
Import custom metadata (clientMetadata) to all data units in a dataset
The following code adds the same custom metadata (clientMetadata) to each data unit in the specified dataset. The code prints the custom metadata along with the data units index within the dataset, so that you can verify that the custom metadata was set correctly.
# Import dependenciesfrom encord import EncordUserClientfrom encord.client import DatasetAccessSettings# Authenticate with Encord using the path to your private keyclient = EncordUserClient.create_with_ssh_private_key( ssh_private_key_path="<private_key_path>")# Specify a dataset to read or write metadata todataset = client.get_dataset("<dataset_hash>")# Fetch the dataset's metadatadataset.set_access_settings(DatasetAccessSettings(fetch_client_metadata=True))# Add metadata to all data units in the dataset.# Replace {"my": "metadata"} with the metadata you want to addfor data_unit, data_row in enumerate(dataset.data_rows): data_row.client_metadata = {"my": "metadata"} data_row.save() print(f"{data_row.client_metadata} - Data Unit: {data_unit}")
Once your custom metadata is included in your Annotate Project (Folder or Dataset), you can create Collections based on your custom metadata and then send those Collections to Annotate.