Predictions must be imported to
Active,
before you can use the Predictions feature on the Explorer page and the
Model Evaluation page.
Model Prediction Support
| Prediction Type | Support |
|---|---|
| Bounding Box | Full support |
| Rotatable Bounding Box | Full support |
| Polygon | Full support |
| Bitmask | Full support |
| Polyline | TP and FP support coming soon |
| Keypoint | TP and FP support coming soon |
How are Prediction Metrics calculated?
Model performance metrics—such as mAP, mAR, Accuracy, and F1-score—and prediction types (True Positive, False Positive, False Negative) are computed for bounding boxes, polygons (segmentations), and bitmasks. Annotate’s labels are treated as the ground truth for evaluating your imported predictions.- Label Rendering: Ground-truth labels are rendered into bitmasks, and all IoU (Intersection over Union) calculations are performed on these bitmasks.
- Prediction Matching: Each prediction is matched to the closest ground-truth label based on IoU.
- Confidence Filtering: Predictions with confidence scores below the specified threshold are discarded.
- IoU Thresholding: For a ground-truth label, the prediction with the highest confidence and an IoU exceeding the threshold is selected as the True Positive (TP). If no such prediction exists, no TP is assigned for that ground-truth label.
- False Positives (FP): Predictions that are not matched to any ground-truth label are classified as False Positives.
When multiple predictions are associated with a single ground-truth label, only one can be marked as the True Positive (TP). The prediction with the highest confidence among those exceeding the IoU threshold is chosen.This ensures a strict one-to-one relationship between ground-truth labels and True Positives.
Important Information
Before going any further, you need to be aware of the differences in behavior between pycoco/TorchMetrics map calculations and Encord’s. The comparisons here were done using ‘torchmetrics=1.2.1’, ‘pycocotools=2.0.6’, and Encord Active. Difference 1 TorchMetrics ignores a class in the mAP calculation (average AP over classes), if there are no ground truth labels of that class in all the images being looked at. Active includes classes in the mAP calculation even if there are no ground truth labels of that class in all the images being looked at Why did we do this? Because Encord Active is inherently dynamic and meant for decomposing model performance based on arbitrary data subsets. This makes model performance more transparent because predictions are not excluded from the performance scores. Difference 2 There is a slight difference in the TP matching algorithm. Encord does not have a prediction match against a different ground truth with a smaller IOU than the initial candidate ground truth if some other prediction with higher confidence matches as a true-positive against that original ground truth, but torchmetrics does. This can result in differences compared to TorchMetrics. The differences become apparent with smaller IOU thresholds, IOU values closer to 1.0 should have a progressively smaller divergence approaching 0 when very close to 1.0. Why did we do this? The difference results in performance improvements when dynamically assigning prediction true-positives depending on the selected IOU threshold.Model Performance
Model Performance - Summary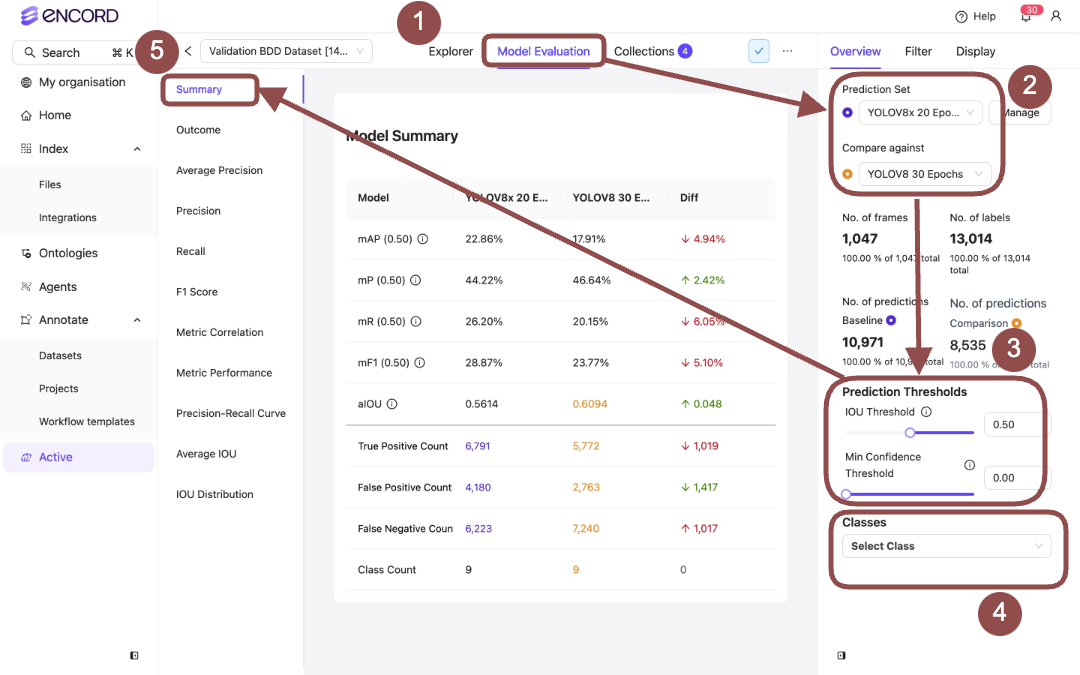 Model Performance - Outcome
Model Performance - Outcome
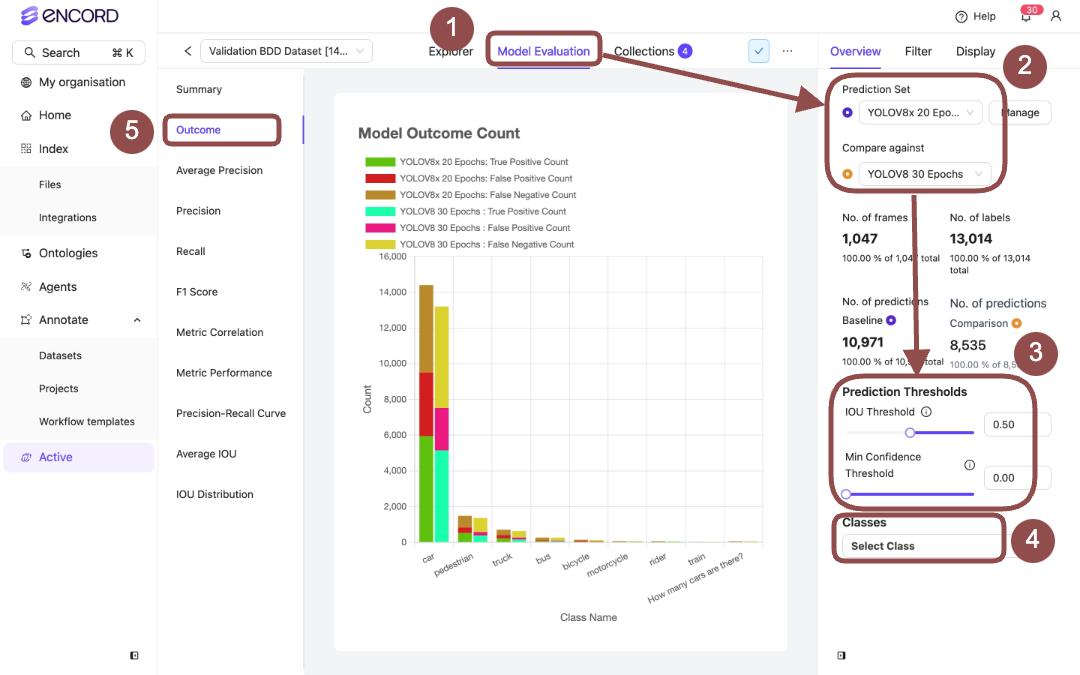 Model Performance - Average Precision
Model Performance - Average Precision
 Model Performance - Precision
Model Performance - Precision
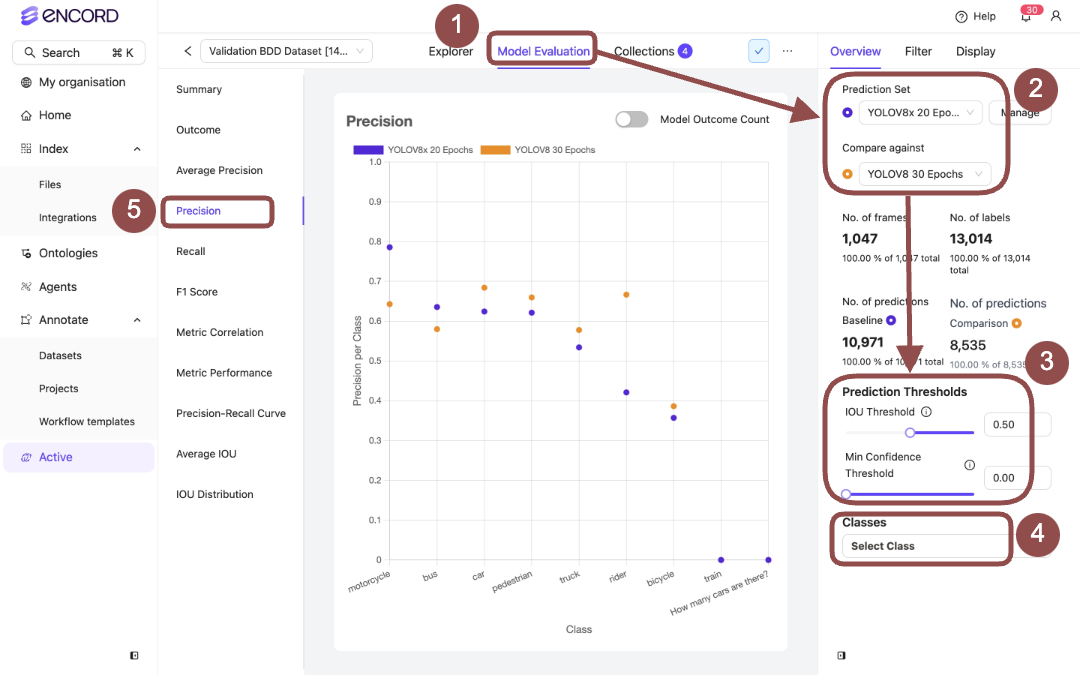 Model Performance - Recall
Model Performance - Recall
 Model Performance - F1 Score
Model Performance - F1 Score
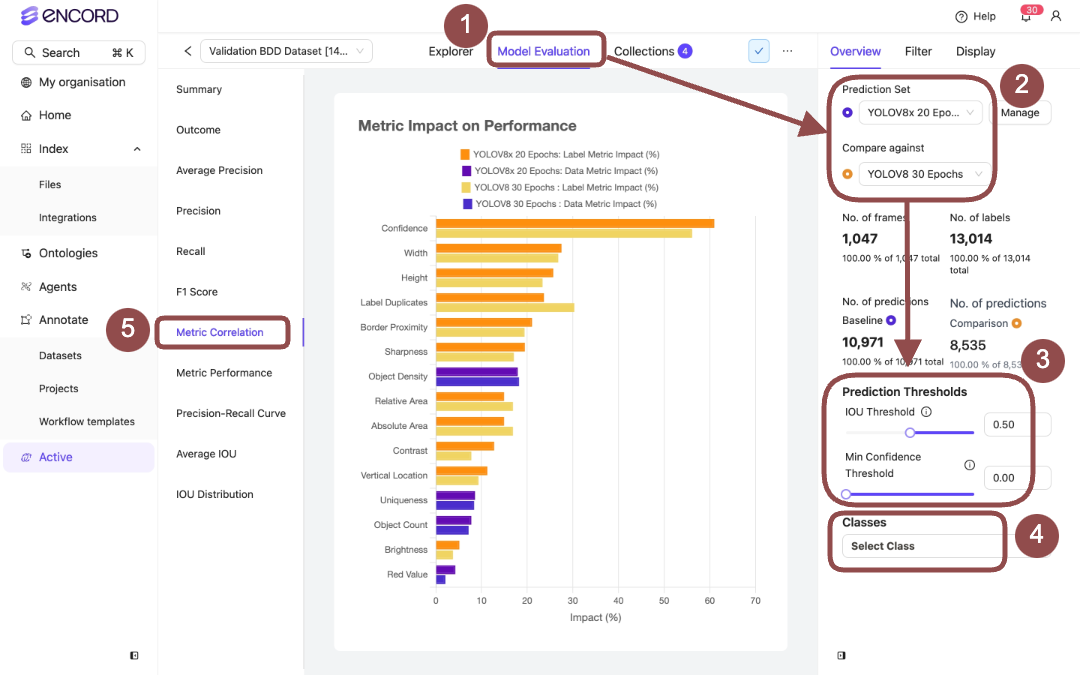
 Model Performance - Metric Correlation
Specifies the impact specific data and label metrics have on your model performance.
Model Performance - Metric Correlation
Specifies the impact specific data and label metrics have on your model performance.
The Impact % is derived from the Pearson correlation coefficient between two values:
- isTruePositive (converted from a boolean to an integer: true = 1, false = 0)
- The corresponding metric value.
- A positive correlation means higher metric values are linked to a higher chance of true positives.
- A negative correlation means higher metric values are linked to a lower chance of true positives.
 Model Performance - Metric Performance
Model Performance - Metric Performance
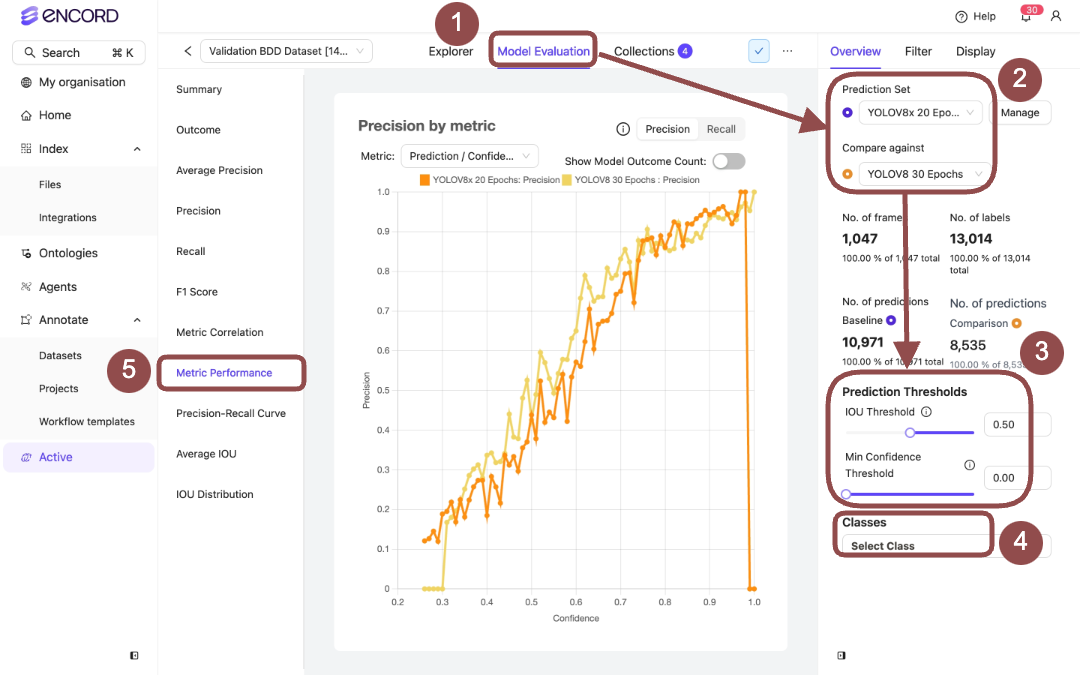 Model Performance - Precision-Recall Curve
Model Performance - Precision-Recall Curve
 Model Performance - Average IOU
Model Performance - Average IOU
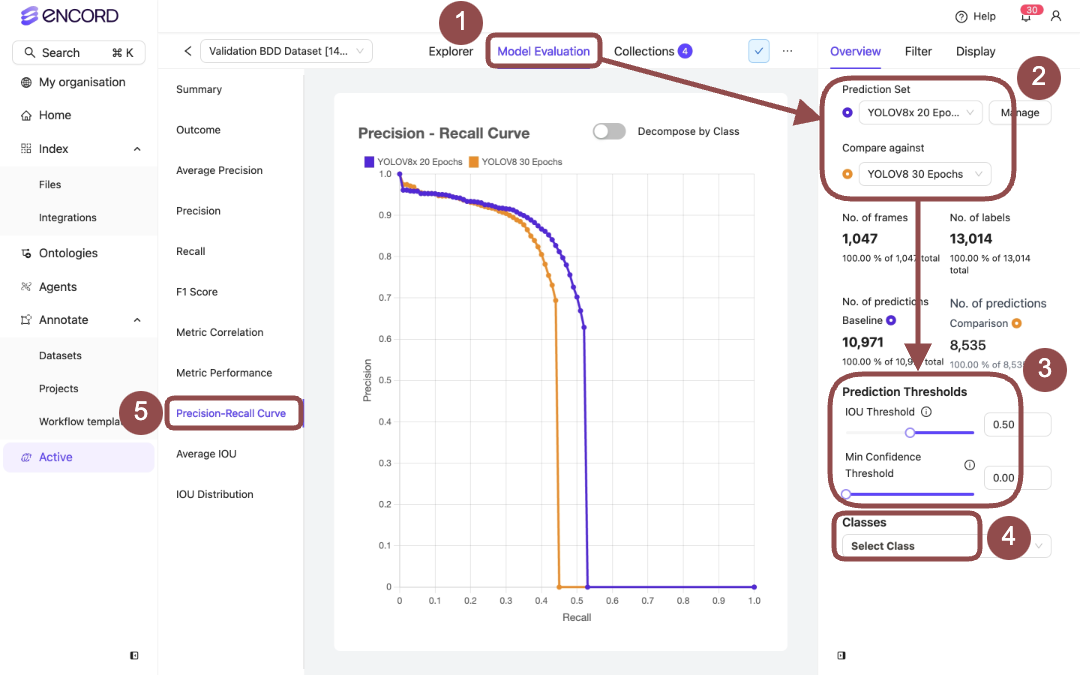
 Model Performance - IOU Distribution
Model Performance - IOU Distribution
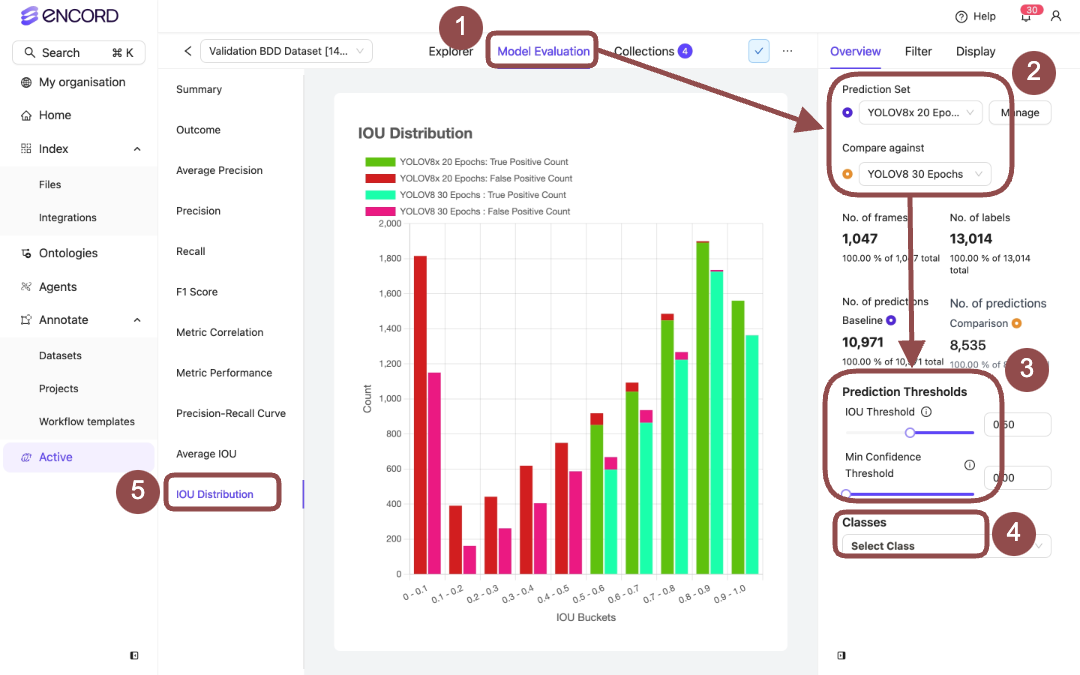 Model Performance - Confusion Matrix
Model Performance - Confusion Matrix
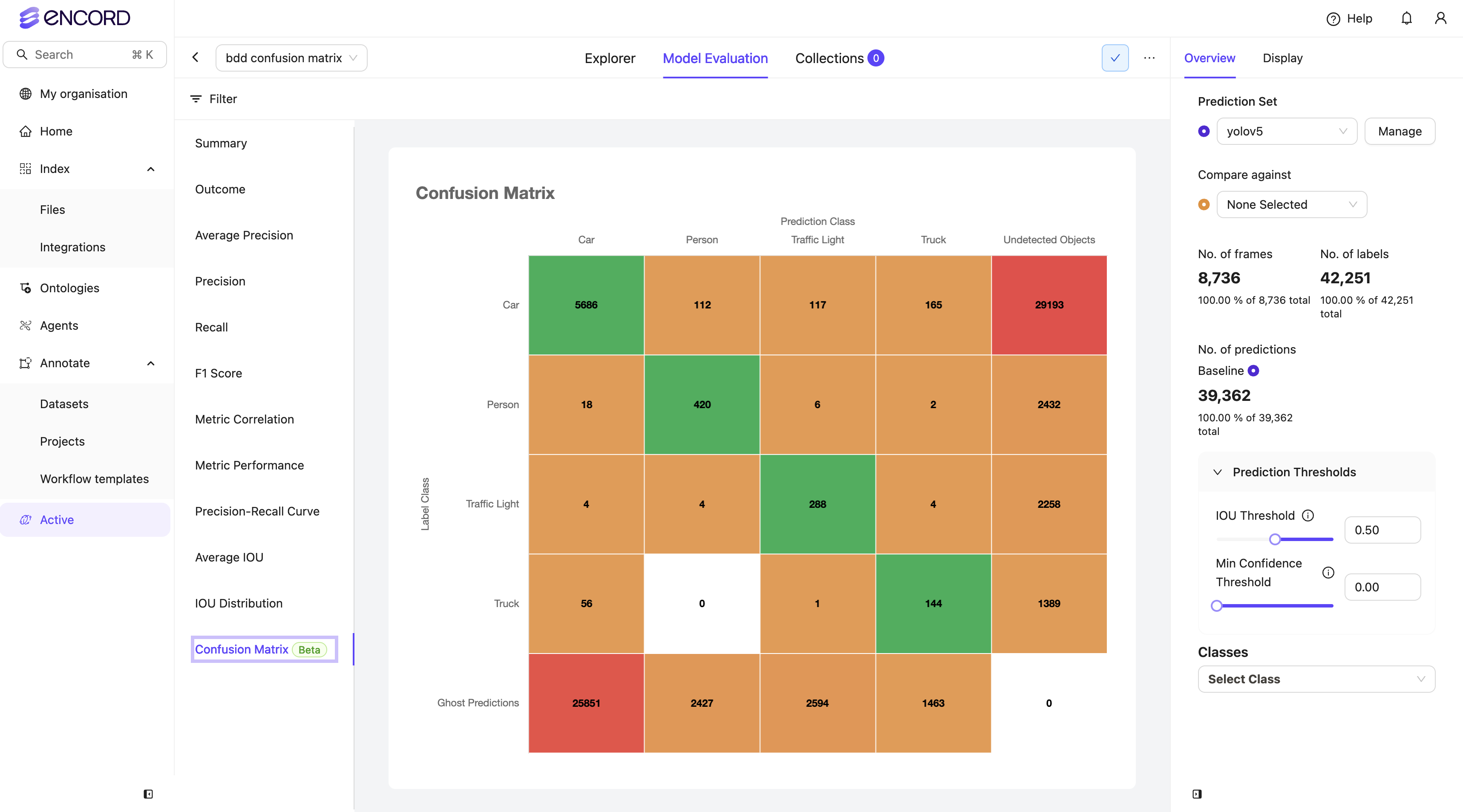
Object Confusion Matrix Matching Algorithm
The Object Confusion Matrix uses a distinct matching algorithm compared to other platform metrics. Here’s how it differs:-
Standard Platform Matching: For most metrics, the matching algorithm processes data item by item and class by class:
- Labels and predictions are grouped by class
- Only labels/predictions within the same class are compared
- This approach is essential for standard object detection workflows
-
Confusion Matrix Matching: For the object confusion matrix:
- All ground truths and predictions are processed together, regardless of class
- The matching algorithm receives the complete set of labels and predictions
- This approach helps evaluate model performance in multi-class scenarios
- Enables identification of cross-class confusion and areas needing improvement
The matching algorithm can be viewed as a black box that takes ground truths
and predictions as input and outputs True Positives (TP), False Positives
(FP), and False Negatives (FN).